Project 1
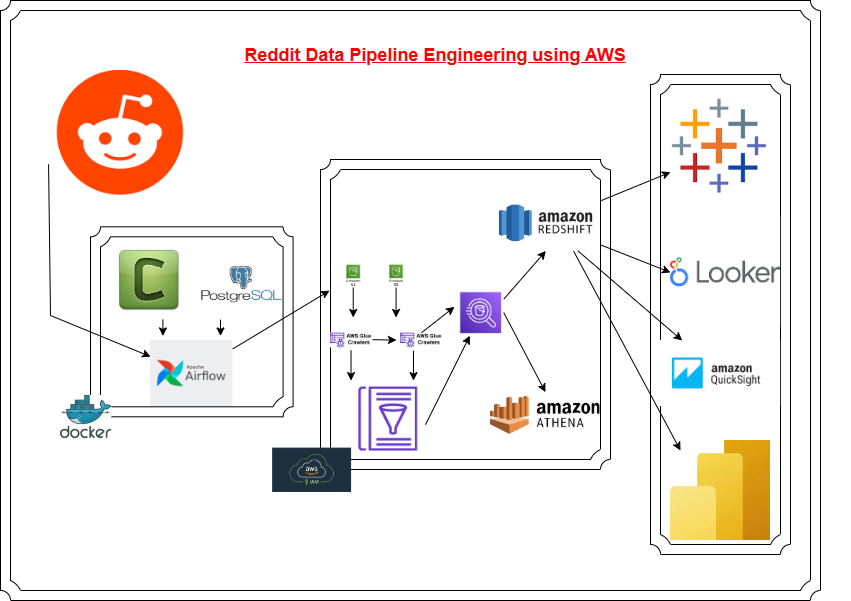
-This project delivers a comprehensive data pipeline solution for the extraction, transformation, and loading (ETL) of Reddit data into an Amazon Redshift data warehouse. The pipeline integrates multiple tools and services, including Apache Airflow, Celery, PostgreSQL, Amazon S3, AWS Glue, Amazon Athena, and Amazon Redshift, to ensure efficient and scalable data processing.
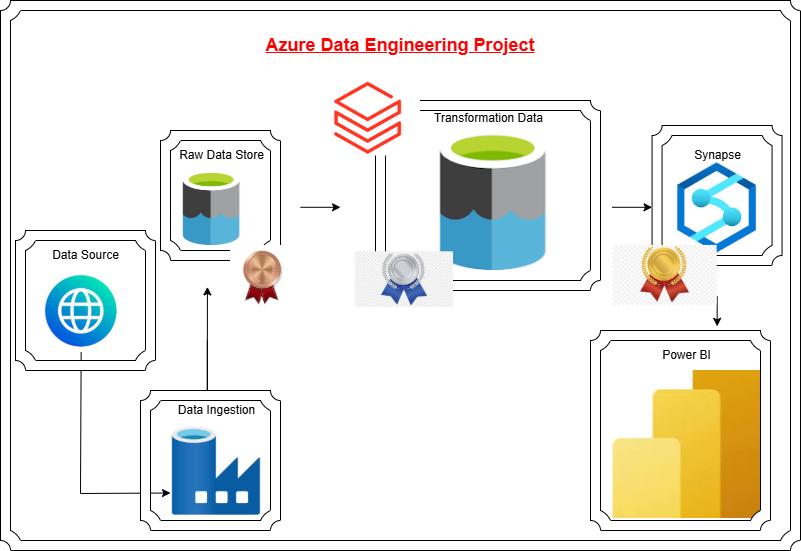
This project is a comprehensive end-to-end Azure Data Engineering initiative. It involves processing data through the complete Azure medallion architecture layers—Bronze, Silver, and Gold—followed by visualization using Power BI to deliver actionable insights.

This project focused on architecting and deploying a comprehensive data integration solution to establish a robust data pipeline between MySQL RDS and Snowflake. The initiative encompassed the complete ETL process: extracting operational data from the MySQL RDS source system, applying necessary transformations to ensure data quality and consistency, and loading the refined datasets into a dedicated source schema within Snowflake's cloud data platform. This end-to-end solution positioned the organization's data assets for advanced analytics and business intelligence initiatives.
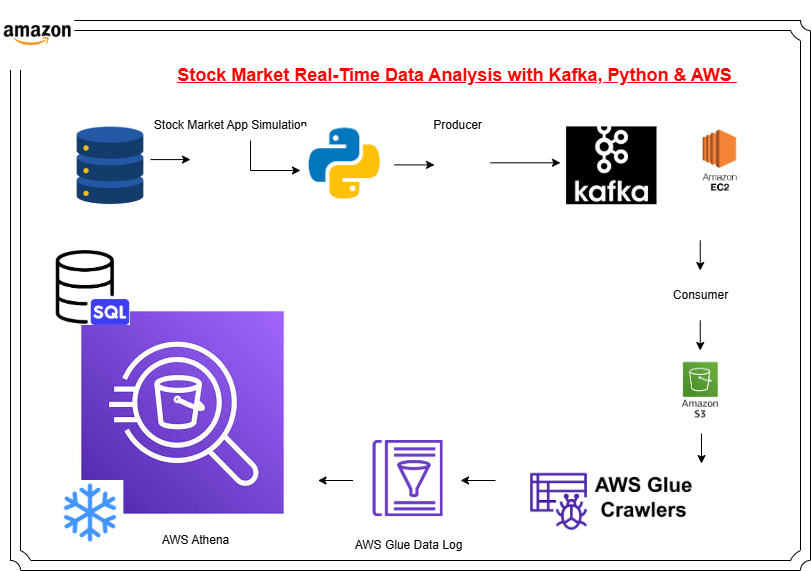
Designed and implemented a comprehensive end-to-end data engineering solution for processing real-time stock market data streams using Apache Kafka. The project leveraged a diverse technology stack including Python for application development and data processing, Apache Kafka for distributed event streaming, and Amazon Web Services (AWS) for cloud infrastructure. Key AWS components included AWS Glue for serverless ETL operations, Amazon Athena for SQL-based analytics, and additional AWS services for data storage and orchestration. This solution demonstrates proficiency in building scalable, real-time data pipelines capable of handling high-throughput financial data with low latency requirements.

Developed a comprehensive date dimension table utilizing a systematic, component-based approach within the data transformation pipeline. The solution leverages the Generate Sequence component to create a foundational integer series, configured through parameterized pipeline variables to ensure flexibility and reusability. The architecture incorporates two strategically positioned Calculator components: the first transforms the numeric sequence into standard calendar date attributes (year, month, day, quarter), while the second computes relative date calculations to support time-based analytics requirements. This implementation demonstrates proficiency in dimensional modeling and ETL design patterns, utilizing core transformation components including Generate Sequence, Calculator transformations, pipeline orchestration, and dynamic variable management.
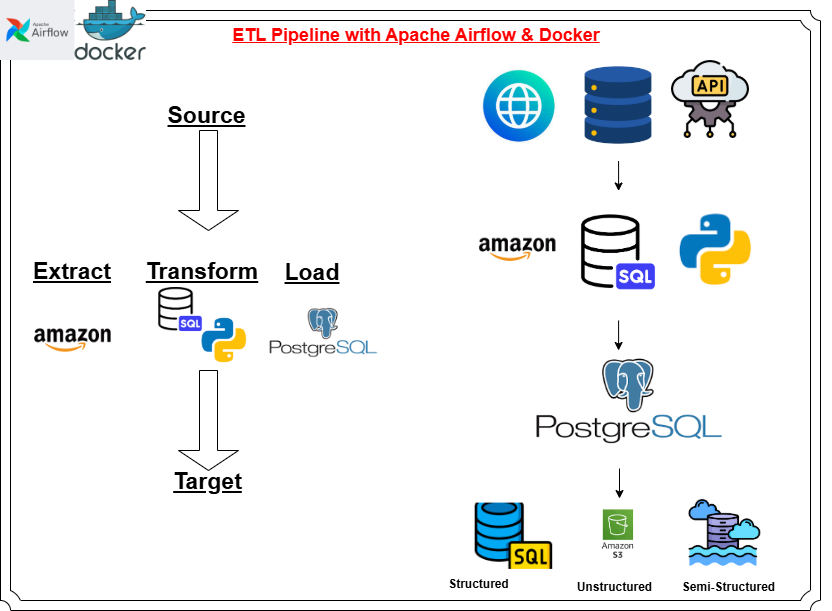
Designed and implemented an automated ETL data pipeline leveraging Apache Airflow for workflow orchestration and scheduling. The solution extracts structured data on data engineering publications from Amazon's platform, applies necessary transformations to ensure data quality and consistency, and loads the refined datasets into a PostgreSQL relational database. The pipeline operates on a scheduled basis, enabling automated, recurring data extraction and synchronization at defined intervals. This project demonstrates expertise in building production-grade, orchestrated data workflows that ensure reliable and timely data availability for downstream analytics and reporting applications.

Conducted comprehensive data analysis on a movie industry dataset sourced from Kaggle, demonstrating advanced Python programming capabilities and analytical methodologies. The analysis was performed within a Jupyter Notebook environment, leveraging industry-standard libraries including Pandas for data manipulation and transformation, Seaborn for statistical visualization, and Matplotlib for custom graphical representations. This project showcases proficiency in exploratory data analysis (EDA), data cleaning, statistical interpretation, and effective data storytelling through visualization techniques applied to real-world entertainment industry data.